분산 환경에서 데이터를 보내려면 수많은 파이프라인이 존재하게 되고 복잡성이 커져 확장하는 데 어려움을 겪게 될 것이다. 이를 해결하기 위해 데이터를 모아주는 "카프카"를 링크드인에서 제작하게 되었다.

카프카는 소스 어플리케이션과 타겟 어플리케이션에 대한 연결을 약하게 하기 위해서 탄생하게 되었다.
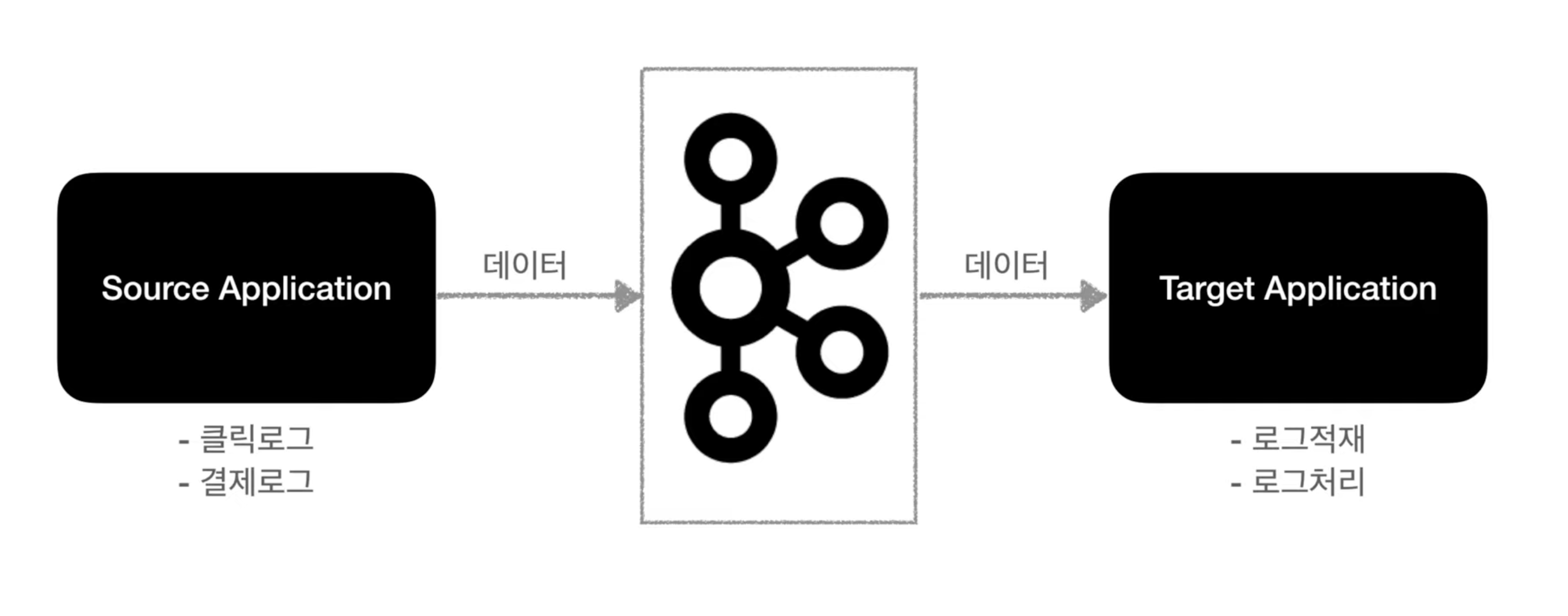
- 프로듀서 : 큐에 데이터에 넣는 역할 (Source Application)
- 컨슈머 : 큐에서 데이터를 가져가는 역할 (Target Application)
고가용성으로 서버가 죽게 되더라도 카프카에서 데이터를 보내기 때문에 가지고 있다가 다른 곳을 보낸다거나 서버가 다시 동작하게 될 때 데이터를 보내는 등이 가능해진다!
'Data Engineering > Kafka' 카테고리의 다른 글
| [Kafka] 아파치 카프카 기초 - 파티셔너 (0) | 2023.07.16 |
|---|---|
| [Kafka] 아파치 카프카 기초 - Broker, Replication, ISR (0) | 2023.07.16 |
| [Kafka] 아파치 카프카 기초 - 토픽 (0) | 2023.07.16 |
| [Kafka] Mac M1환경에서 Kafka/Zookeeper 서버 (0) | 2023.07.15 |
| [Kafka] 카프카 개념 (0) | 2023.07.15 |