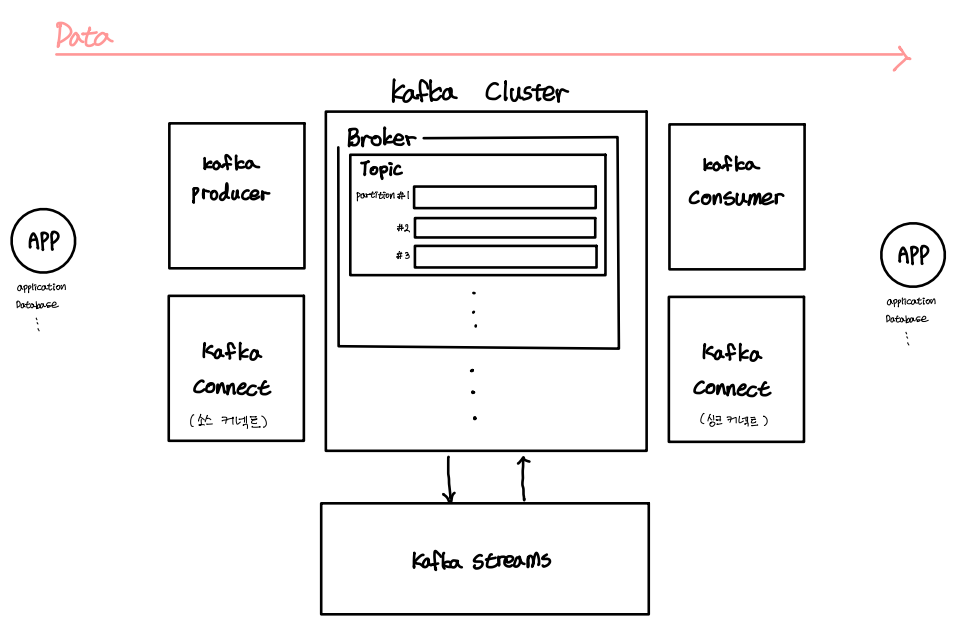
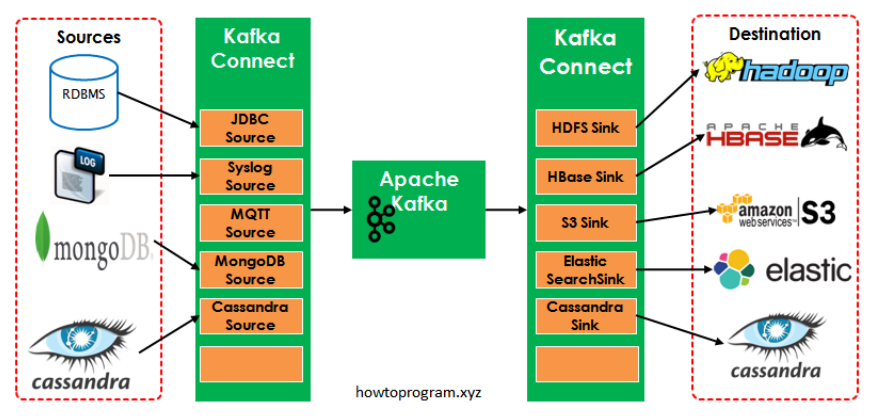
EC2에 Kafka를 설치해보려고 하는데 관리하기 쉽도록 오픈 소스인 provectuslabs/kafka-ui를 사용하려고 한다.
- Docker-compose로 설치하는 방법
- Docker 없이 수행하는 방법
두가지로 진행해보려고 한다.
왜냐하면 Docker-compose로 실행을 했더니 외부에서 해당 카프카를 접속하는데 계속 실패를 했다... (개발 환경이었기 때문에 접근이 불가능했지만 배포 후에는 잘 동작한다)
그래서 도커 없이 Kafka를 실행시키는 방식으로 구현했지만 기록으로 남겨둔다.
1. Docker-compose로 설치
mkdir kafka
cd kafka
vi docker-compose.ymlversion: '3.8'
services:
zookeeper-1:
image: confluentinc/cp-zookeeper:5.5.1
ports:
- '32181:32181'
environment:
ZOOKEEPER_CLIENT_PORT: 32181
ZOOKEEPER_TICK_TIME: 2000
kafka-1:
image: confluentinc/cp-kafka:5.5.1
ports:
- '9092:9092'
depends_on:
- zookeeper-1
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:32181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka-1:29092,EXTERNAL://localhost:9092
KAFKA_DEFAULT_REPLICATION_FACTOR: 1
KAFKA_NUM_PARTITIONS: 1
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8989:8080"
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka-1:29092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper-1:22181
sudo docker-compose up -d
배포환경에서는 같은 네트워크를 잡아주고 해당 도커 네임(http://kafka1-1:9092)으로 레코드를 보내면 잘 전송이 되지만 개발 환경에서 해당 브로커로 데이터를 보내는데 실패했다. 일단, 개발환경이기 때문에 Docker없이 데이터를 전송하기로 결정하고 아래의 환경으로 개발했다.
2. Docker 없이 수행
sudo apt-get install wget
# kafka download
wget https://archive.apache.org/dist/kafka/3.2.1/kafka_2.13-3.2.1.tgz
tar -xzf kafka_2.13-3.2.1.tgz
cd kafka_2.13-3.2.1/
vi config/server.properties
config/server.properties 설정
1. 외부 IP 알아내기
curl ifconfig.me
2. 해당 IP로 config/server.properties 설정
#listeners=PLAINTEXT://:9092
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://{외부 IP}:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
3. Kafka 실행
# zookeeper 먼저 실행
./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
# kafka server 실행
./bin/kafka-server-start.sh -daemon ./config/server.properties
Kafka 설치 끝!!
이제 Kafka를 관리하기 위한 UI를 설치해보려고 한다.
kafka-UI 설치
docker run -p 8989:8080 \\
-e KAFKA_CLUSTERS_0_NAME=local \\
-e KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS={카프카가 동작하는 외부 IP}:9092 \\
-e KAFKA_CLUSTERS_0_ZOOKEEPER={주키퍼가 동작하는 외부 IP}:2183 \\
-d provectuslabs/kafka-ui:latestKafka UI로 접근
UI 수행되는지 확인
혹시 접근이 안된다면 아래에 있는 방화벽 설정 확인!!
이렇게 토픽을 생성하거나 파티션을 관리하는 등 편리한 ui를 제공해준다.
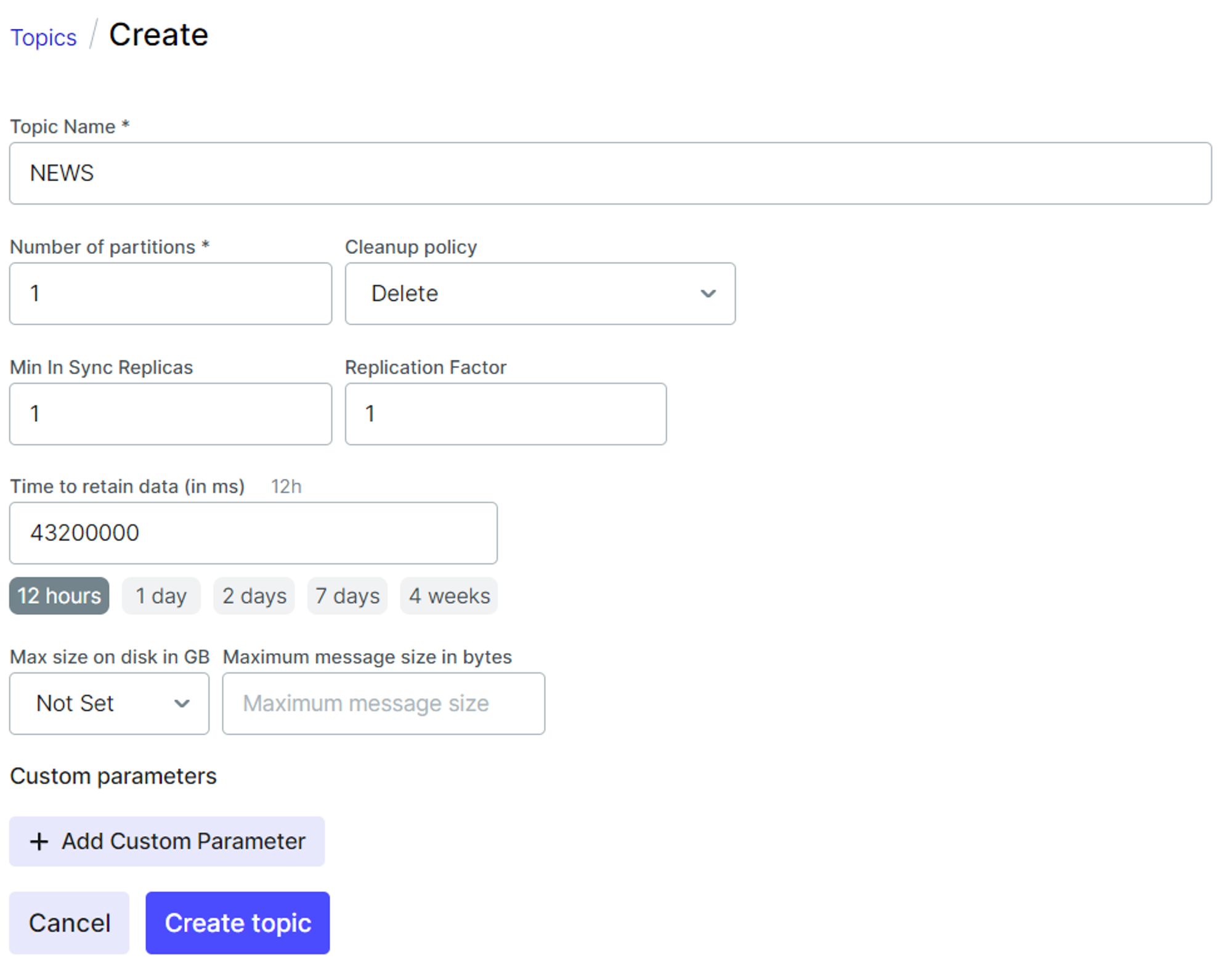
이제 외부에서 해당 카프카로 데이터를 전송해보도록 하겠습니다.
방화벽 설정
일단 방화벽부터 설정해서 외부에서 해당 포트로 접근하도록 허가해줍니다.
sudo ufw enable
// kafka
sudo ufw allow 9092
// kafka ui (혹시 Kafka UI 접속이 안된다면 다음처럼 설정)
sudo ufw allow 8989
이제 EC2가 아닌 local 컴퓨터(내 컴퓨터)에서 카프카 프로듀서로 데이터를 전송해보도록 하겠습니다.
내 컴퓨터의 터미널에서
카프카 다운로드
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/3.2.1/kafka_2.13-3.2.1.tgz
tar -xzf kafka_2.13-3.2.1.tgz
카프카 프로듀서(내 컴퓨터) -> 카프카 브로커(EC2)
cd kafka_2.13-3.2.1.tgz
// 토픽 리스트를 확인
bin/kafka-topics.sh --bootstrap-server {Kafka가 있는 EC2 외부 IP}:9092 --list
// 토픽에 데이터 전송하기
bin/kafka-console-producer.sh --bootstrap-server {Kafka가 있는 EC2 외부 IP}:9092 --topic {TOPIC NAME}
이제 UI를 통해서 데이터가 잘 받아져왔는지 확인할 수 있다!!!
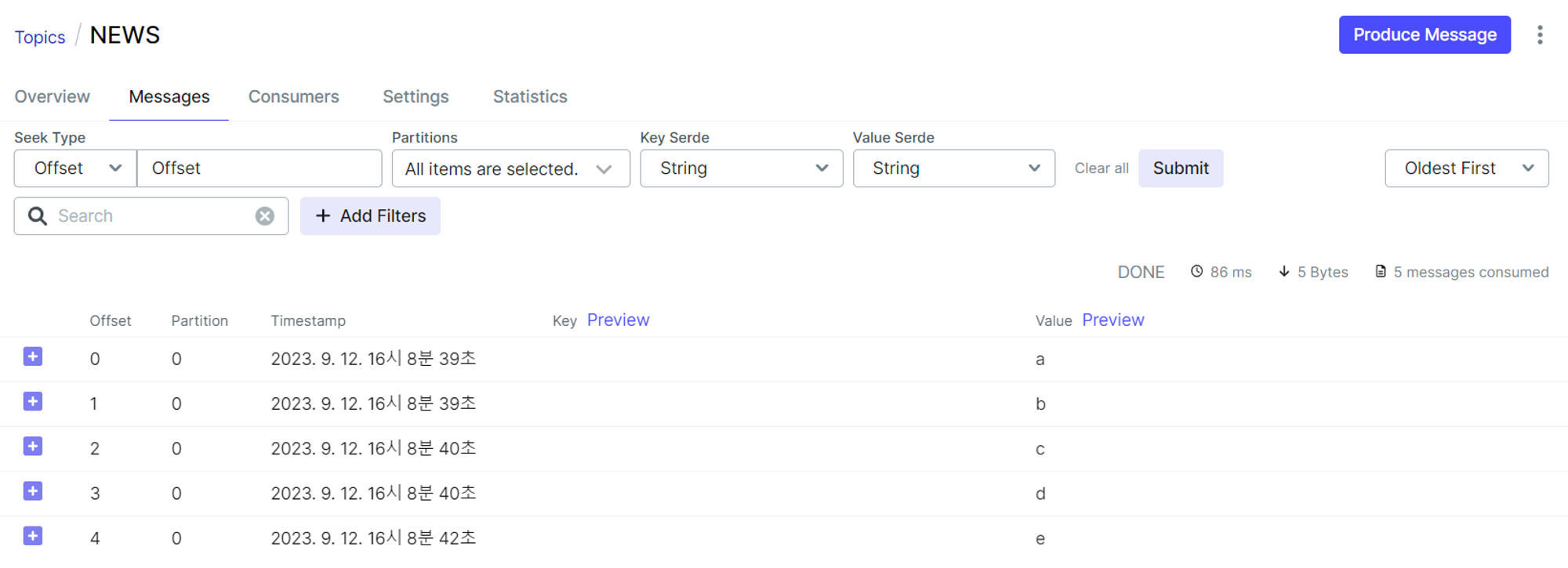
참고
https://velog.io/@jwpark06/AWS-EC2에-Kafka-설치하기#2-topic-생성
'Data Engineering > Kafka' 카테고리의 다른 글
| [Kafka] Kafka Connector를 이용해서 HDFS에 저장 (0) | 2023.09.28 |
|---|---|
| [Kafka] Kafka Connector 정리 (0) | 2023.09.28 |
| [Kafka] 카프카 개념 정리 (0) | 2023.09.28 |
| [Kafka] 아파치 카프카 기초 - 컨슈머 Lag과 모니터링 (0) | 2023.07.16 |
| [Kafka] 아파치 카프카 기초 - 파티셔너 (0) | 2023.07.16 |